
A Foundation Model for Human–AI Collaboration in Medical Literature Mining là nghiên cứu đột phá được công bố trên Nature Communications (2025) bởi nhóm tác giả Zifeng Wang (Keiji AI, Seattle, Hoa Kỳ) và Jimeng Sun (University of Illinois Urbana–Champaign) cùng 20 nhà nghiên cứu từ nhiều tổ chức y học hàng đầu như Harvard, NIH, và Weill Cornell Medicine.
Công trình giới thiệu LEADS — mô hình ngôn ngữ nền tảng (foundation model) dành riêng cho khai thác y văn, được huấn luyện trên hơn 633.759 mẫu dữ liệu từ 21.335 tổng quan hệ thống, 453.625 bài báo thử nghiệm lâm sàng và 27.015 cơ sở dữ liệu ClinicalTrials.gov. LEADS là bước tiến quan trọng trong việc kết hợp giữa con người và trí tuệ nhân tạo để tăng tốc quá trình tổng quan y học bằng chứng.
BIODAS Team chia sẻ bài viết này nhằm giới thiệu hướng phát triển AI chuyên biệt miền y học và tiềm năng hợp tác giữa Người – AI trong tổng hợp tri thức y học.

1. Đặt vấn đề
Các tổng quan hệ thống (systematic reviews) và phân tích gộp (meta-analyses) đóng vai trò then chốt trong y học bằng chứng, song lại tiêu tốn rất nhiều nguồn lực. Một nghiên cứu cho thấy trung bình mỗi tổng quan cần đến 67 tuần để hoàn thành, với chi phí ước tính trên 17 triệu USD/năm cho mỗi viện nghiên cứu hoặc công ty dược lớn (Borah et al., BMJ Open 2017).
Khi khối lượng y văn y học tăng vọt lên hơn 35 triệu bài báo trên PubMed, việc sàng lọc và trích xuất dữ liệu thủ công không còn khả thi (Uttley et al., J Clin Epidemiol 2023). AI đã được thử nghiệm trong các bước như tạo từ khóa tìm kiếm (Wang et al., SIGIR 2023), sàng lọc trích dẫn (Sanghera et al., JAMIA 2025), và tóm tắt thử nghiệm lâm sàng (Peng et al., Nat Med 2023), nhưng hầu hết vẫn là các mô hình đơn nhiệm, thiếu tính tổng quát và độ tin cậy để thay thế con người.
Do đó, nhóm nghiên cứu phát triển LEADS với mục tiêu tạo ra một nền tảng AI có thể học theo hướng dẫn (instruction-based), hoạt động đa nhiệm, và cộng tác cùng chuyên gia để nâng cao năng suất tổng quan y học.

2. Mô hình LEADS và bộ dữ liệu huấn luyện
LEADS được xây dựng dựa trên mô hình Mistral-7B và tinh chỉnh bằng bộ dữ liệu LEADSInstruct, gồm hơn 630.000 cặp hướng dẫn–phản hồi từ 21.000 tổng quan hệ thống liên kết với dữ liệu ClinicalTrials.gov. Bộ dữ liệu này bao phủ sáu nhiệm vụ cốt lõi:
- Tạo câu truy vấn tìm kiếm (Search query generation)
- Đánh giá tiêu chí chọn nghiên cứu (Study eligibility assessment)
- Trích xuất đặc điểm nghiên cứu (Study characteristic extraction)
- Thiết kế nhóm can thiệp (Arm design extraction)
- Thống kê người tham gia (Participant statistics extraction)
- Kết quả thử nghiệm (Trial result extraction)
LEADS được huấn luyện bằng phương pháp instruction tuning và tối ưu hóa với thuật toán AdamW, đạt khả năng xử lý văn bản lên đến 30.000 tokens — tương đương khoảng 15–20 trang báo khoa học. Mô hình được đánh giá trên tập thử nghiệm giả lập “pseudo-prospective” gồm các bài báo xuất bản sau năm 2025 để kiểm chứng khả năng tổng quát hóa.
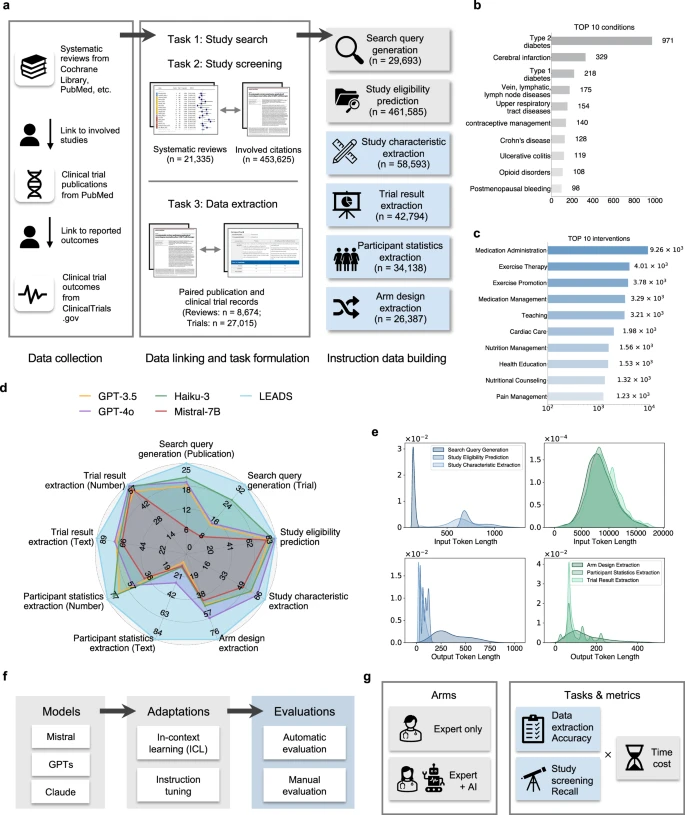
(a) LEADSInstruct bao gồm hơn 20.000 tổng quan hệ thống, 453.000 bài báo khoa học, và 27.000 thử nghiệm lâm sàng được liên kết từ nhiều nguồn dữ liệu khác nhau. Một phương pháp lai (hybrid approach) được áp dụng để chuyển đổi các dữ liệu liên kết này thành bộ dữ liệu huấn luyện theo hướng dẫn (instruction data), bao phủ sáu nhóm nhiệm vụ chính trong khai thác y văn. (b) Biểu đồ cột thể hiện số lượng các tổng quan hệ thống theo từng nhóm bệnh lý (conditions). (c) Biểu đồ cột thể hiện số lượng các tổng quan hệ thống theo từng nhóm can thiệp (interventions). (d) Phân tích so sánh hiệu năng giữa mô hình LEADS và các mô hình AI tiên tiến, bao gồm cả mô hình thương mại độc quyền và mã nguồn mở. Các chỉ số đánh giá bao gồm: Recall cho nhiệm vụ tạo truy vấn tìm kiếm (search query generation), Recall@50 cho nhiệm vụ đánh giá tính phù hợp của nghiên cứu (study eligibility assessment), và Accuracy cho các nhiệm vụ còn lại. (e) Biểu đồ mật độ (density plot) mô tả phân bố số lượng tokens trong phần đầu vào và đầu ra của các tập dữ liệu huấn luyện theo hướng dẫn. (f) Hình minh họa thiết lập thí nghiệm (experimental setups). (g) Hình minh họa thiết kế nghiên cứu người dùng (user study setup).
3. Hiệu năng và thử nghiệm thực tế
Trong các bài kiểm tra với hơn 10.000 tổng quan hệ thống, LEADS thể hiện vượt trội so với các mô hình tiên tiến như GPT-4o, GPT-3.5, Haiku-3, và BioMistral. Ở nhiệm vụ tìm kiếm, LEADS đạt Recall 24,68%–32,11%, cao hơn 3–7% so với GPT-4o, và trong các thử nghiệm sàng lọc, LEADS đạt Recall@50 = 0,82, tương đương GPT-4o (0,80–0,81).
Trong nhiệm vụ trích xuất dữ liệu, LEADS cho thấy độ chính xác vượt trội:
- Đặc điểm nghiên cứu: 0,68 so với 0,55 (GPT-4o)
- Thiết kế nhóm can thiệp: 0,53 so với 0,45
- Thống kê người tham gia: 0,94 so với 0,55
- Kết quả thử nghiệm: 0,78 so với 0,45
Các thử nghiệm thực tế với 15 bác sĩ lâm sàng và 2 nhà nghiên cứu cho thấy LEADS giúp rút ngắn thời gian sàng lọc 20,8% và trích xuất dữ liệu 26,9% mà không làm giảm độ chính xác — chứng minh vai trò như “trợ lý AI” đáng tin cậy trong nghiên cứu y học.

4. Hợp tác Người – AI trong tổng quan y văn
Mục tiêu chính của LEADS không phải thay thế chuyên gia, mà là **tăng cường năng lực hợp tác giữa con người và AI**. Trong thử nghiệm hai nhóm (Expert-only vs. Expert+AI), nhóm sử dụng LEADS đạt Recall trung bình 0,81 so với 0,78 của nhóm độc lập, đồng thời giảm hơn 130 giây cho mỗi nhiệm vụ.
Các chuyên gia đánh giá cao khả năng của LEADS trong việc:
- Phân loại nhanh nghiên cứu không phù hợp bằng điểm “-1”;
- Đưa ra lý do giải thích theo tiêu chí PICO;
- Đề xuất ưu tiên nghiên cứu có độ liên quan cao để con người xem xét;
- Giúp tăng độ tin cậy trong các quyết định chọn bài và trích xuất dữ liệu.
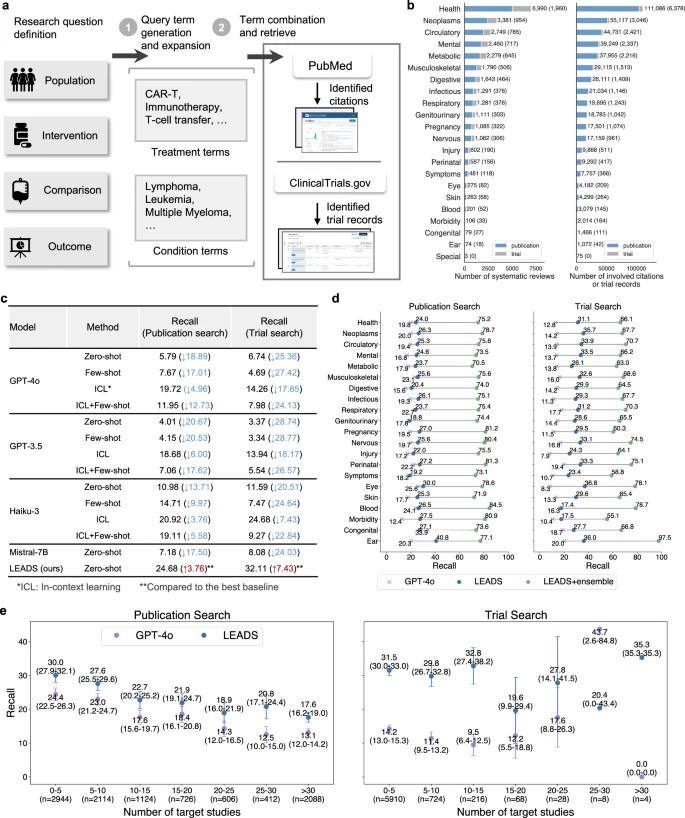
(a) Minh họa quy trình hoạt động của LEADS: mô hình nhận định nghĩa câu hỏi nghiên cứu, tạo truy vấn tìm kiếm (search query generation) và truy xuất các trích dẫn (citations) phù hợp từ kho y văn. (b) Phân bố các chủ đề bệnh lý (condition topics) của các tổng quan hệ thống và các trích dẫn liên quan trong tập dữ liệu. (c) Hiệu năng của LEADS và các mô hình hàng đầu khác trong nhiệm vụ tạo truy vấn tìm kiếm, được đánh giá bằng chỉ số Recall (tỷ lệ nghiên cứu được truy xuất thành công). Thông tin trong ngoặc đơn biểu thị mức chênh lệch hiệu năng giữa các mô hình cơ sở (baseline) so với LEADS, hoặc giữa LEADS và mô hình tốt nhất trong cùng nhiệm vụ. (d) So sánh hiệu năng theo từng chủ đề (topic-wise) giữa LEADS và GPT-4o, dựa trên giá trị Recall thu được từ các truy vấn tìm kiếm. Ký hiệu LEADS+ ensemble chỉ phương pháp kết hợp nhiều truy vấn tìm kiếm (ensemble) để tăng độ bao phủ. (e) So sánh hiệu năng giữa LEADS và GPT-4o khi số lượng nghiên cứu mục tiêu trong mỗi tổng quan thay đổi. Thanh sai số (error bar) biểu thị khoảng tin cậy 95% (95% confidence interval) của giá trị trung bình, được lược bỏ khi cỡ mẫu nhỏ hơn 10.
5. Ý nghĩa và tác động đối với y học bằng chứng
LEADS là minh chứng cho xu hướng phát triển các foundation model chuyên biệt trong y học, nơi mô hình nhỏ, được tinh chỉnh bằng dữ liệu chất lượng cao, có thể vượt trội hơn mô hình tổng quát lớn. Kết quả này đồng thuận với hướng đi của các nghiên cứu như Panacea (Lin et al., medRxiv 2024) và BioMistral (Labrak et al., ACL 2024), cho thấy tiềm năng của các mô hình AI “có miền” trong hỗ trợ nghiên cứu, thử nghiệm lâm sàng và chính sách y tế.
LEADS không chỉ giảm thời gian tổng hợp bằng chứng mà còn giúp tăng độ minh bạch, giảm sai sót con người, và mở đường cho mô hình “AI làm việc cùng bác sĩ” trong nghiên cứu lâm sàng.
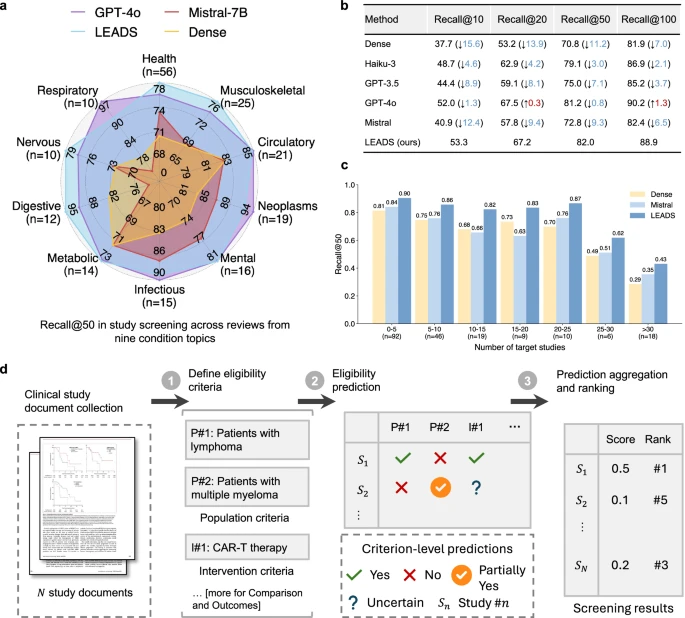
(a) Biểu đồ radar thể hiện Recall@50, so sánh hiệu năng của LEADS với các mô hình ngôn ngữ lớn (LLM) tiên tiến và phương pháp truy hồi đặc trưng dày đặc (dense retrieval) trên nhiều chủ đề bệnh lý (condition topics) khác nhau trong các tổng quan hệ thống. (b) Hiệu năng Recall của LEADS được so sánh với các mô hình LLM khác và phương pháp dense retrieval. Thông tin trong ngoặc đơn thể hiện mức thay đổi hiệu năng của các mô hình cơ sở (baseline) so với LEADS. (c) So sánh hiệu năng giữa LEADS và các mô hình cơ sở khi số lượng nghiên cứu mục tiêu (target studies) trong mỗi tổng quan thay đổi. (d) Minh họa quy trình LEADS nhận các tiêu chí chọn và loại nghiên cứu (inclusion/exclusion criteria) được xác định theo các yếu tố PICO (Population, Intervention, Comparison, Outcome), thực hiện dự đoán tính phù hợp (eligibility prediction) và xếp hạng các nghiên cứu mục tiêu theo mức độ đáp ứng tiêu chí.
6. Giới hạn nghiên cứu và hướng phát triển
Dù đạt kết quả ấn tượng, LEADS vẫn tồn tại một số giới hạn:
- Chất lượng dữ liệu huấn luyện phụ thuộc vào tính chính xác của các tổng quan hệ thống và dữ liệu ClinicalTrials.gov.
- Thử nghiệm người dùng còn quy mô nhỏ (16 chuyên gia), chưa phản ánh đầy đủ môi trường làm việc thực tế.
- LEADS yêu cầu cấu hình GPU ≥ 20GB VRAM để triển khai cục bộ, hạn chế khả năng tiếp cận của cộng đồng.
- Chưa bao gồm các bước đánh giá chất lượng nghiên cứu (risk of bias) hay độ chắc chắn của bằng chứng (certainty).
Trong tương lai, nhóm tác giả định tích hợp LEADS vào nền tảng TrialMind để tự động hóa quá trình tổng quan hệ thống, đồng thời mở rộng sang các lĩnh vực như dược lý học, chính sách y tế và phát triển thuốc.

(a) Độ chính xác trung bình (Mean accuracy) của LEADS và các mô hình ngôn ngữ lớn (LLMs) khác trong bốn nhiệm vụ trích xuất dữ liệu, được đánh giá bằng phương pháp tự động (automatic evaluation). Các giá trị trong ngoặc đơn biểu thị khoảng tin cậy 95% (95% confidence intervals). (b) Độ chính xác của LEADS và các LLMs khác trong bốn nhiệm vụ trích xuất dữ liệu, được đánh giá bằng phương pháp thủ công (manual evaluation). (c) Độ chính xác của LEADS và các LLMs khác theo độ dài khác nhau của tài liệu đầu vào trong bốn nhiệm vụ trích xuất dữ liệu, được đánh giá bằng phương pháp thủ công. Đường màu đỏ biểu thị đường hồi quy (regression line) thể hiện mối quan hệ giữa độ chính xác trung bình và độ dài đầu vào; vùng được tô bóng thể hiện khoảng tin cậy 95%. Ký hiệu ρ (rho) biểu thị hệ số tương quan Pearson, và P đại diện cho giá trị p hai phía (two-sided p-value) dùng để kiểm định giả thuyết không có mối tương quan giữa độ dài đầu vào và độ chính xác. (d) Minh họa cách LEADS thực hiện bốn nhiệm vụ trích xuất dữ liệu thông qua học trong ngữ cảnh (in-context learning). Dựa trên định nghĩa của trường dữ liệu mục tiêu (target field) và các nhóm đối tượng (cohorts), LEADS xử lý các tài liệu nghiên cứu và tạo ra kết quả có cấu trúc (structured outputs).
7. Đề xuất ứng dụng cho Việt Nam
- Chính sách: Thiết lập khung pháp lý cho ứng dụng AI trong nghiên cứu y học, bảo vệ dữ liệu và quyền riêng tư bệnh nhân.
- Hạ tầng dữ liệu: Xây dựng cơ sở dữ liệu thử nghiệm lâm sàng mở (Vietnam Clinical Data Repository) tích hợp với PubMed và WHO ICTRP.
- Đào tạo nhân lực: Phát triển chương trình đào tạo “Health Data Science & AI Literacy” cho bác sĩ và nhà nghiên cứu.
- Ứng dụng thử nghiệm: Thí điểm sử dụng mô hình như LEADS trong Bộ Y tế, các bệnh viện trung ương (Bạch Mai, Chợ Rẫy, 108) để hỗ trợ tổng quan thuốc và hướng dẫn điều trị.
- Hợp tác quốc tế: Tham gia mạng lưới nghiên cứu như Global Evidence Synthesis Initiative (GESI) và Cochrane AI Taskforce.
Việc triển khai mô hình như LEADS sẽ giúp Việt Nam rút ngắn quy trình đánh giá công nghệ y tế (HTA), cải thiện năng lực tổng hợp bằng chứng, và thúc đẩy chính sách y tế dựa trên dữ liệu trong kỷ nguyên chuyển đổi số y tế.
(a) Sơ đồ thiết lập hai nhóm thử nghiệm: nhóm chỉ chuyên gia (Expert-only, Nhánh A) và nhóm chuyên gia kết hợp AI (Expert+AI, Nhánh B) trong nhiệm vụ sàng lọc nghiên cứu (study screening). Hai nhóm được so sánh về Recall (độ bao phủ) để đánh giá chất lượng kết quả, và thời gian trung bình cho mỗi chủ đề tổng quan để đánh giá tốc độ làm việc. (b) Phân bố chuyên môn và trình độ của các chuyên gia tham gia nghiên cứu thử nghiệm người dùng. (c) Số lượng nghiên cứu y học được sàng lọc và lựa chọn theo từng chủ đề tổng quan bởi các chuyên gia tham gia. (d) So sánh chất lượng kết quả tổng thể và thời gian trung bình trên mỗi nghiên cứu giữa hai nhóm trong nhiệm vụ sàng lọc. Mức độ ý nghĩa thống kê được xác định bằng kiểm định U của Mann–Whitney hai phía (two-sided Mann–Whitney U test), với ký hiệu: "ns = không có ý nghĩa thống kê"; "= p < 0,05"; "** = p < 0,01"; "*** = p < 0,001" (Quy ước này được áp dụng tương tự cho các hình khác nếu không ghi chú riêng). (e) Sơ đồ thiết lập hai nhóm (Nhánh A: Expert-only và Nhánh B: Expert+AI) trong nhiệm vụ trích xuất dữ liệu (data extraction). Hai nhóm được so sánh về độ chính xác (accuracy) để đánh giá chất lượng, và thời gian trung bình cho mỗi tác vụ trích xuất để đánh giá tốc độ. (f) Chất lượng sàng lọc giữa các nhóm thay đổi tùy theo mức độ khó của chủ đề tổng quan, được phân tầng theo thời gian xử lý trung bình mỗi chủ đề. Nhóm Expert+AI cho thấy hiệu năng ổn định và cao hơn nhóm chỉ chuyên gia, đặc biệt trong các nhiệm vụ phức tạp và tốn nhiều thời gian. (g) So sánh độ chính xác trung bình và thời gian thực hiện giữa hai nhóm trong các nhiệm vụ trích xuất dữ liệu. (h) So sánh chi tiết độ chính xác và thời gian trung bình cho từng chủ đề trích xuất dữ liệu giữa hai nhóm. Mỗi điểm dữ liệu biểu thị giá trị trung bình của độ chính xác hoặc thời gian dành cho các tác vụ trích xuất thuộc cùng một chủ đề.
8. Tài liệu tham khảo
- Borah R, Brown AW, Capers PL, Kaiser KA. Analysis of time and workers needed to conduct systematic reviews. BMJ Open. 2017;7:e012545.
- Uttley L, et al. The problems with systematic reviews: a living systematic review. J Clin Epidemiol. 2023;156:30–41.
- Wang S, Scells H, Koopman B, Zuccon G. Can ChatGPT write a good Boolean query for systematic review literature search? SIGIR 2023.
- Sanghera R, et al. High-performance automated abstract screening with LLM ensembles. J Am Med Inform Assoc. 2025;32:893–904.
- Peng Y, Rousseau JF, Weng C. AI-generated text may have a role in evidence-based medicine. Nat Med. 2023;29:1593–1594.
- Labrak Y, et al. BioMistral: open-source pretrained LLMs for medical domains. ACL 2024.
- Lin J, Xu H, Wang Z, Sun J. Panacea: a foundation model for clinical trial search and design. medRxiv 2024.
- Wang Z, Sun J. A Foundation Model for Human–AI Collaboration in Medical Literature Mining. Nature Communications. 2025;16:8361. DOI: 10.1038/s41467-025-62058-5.